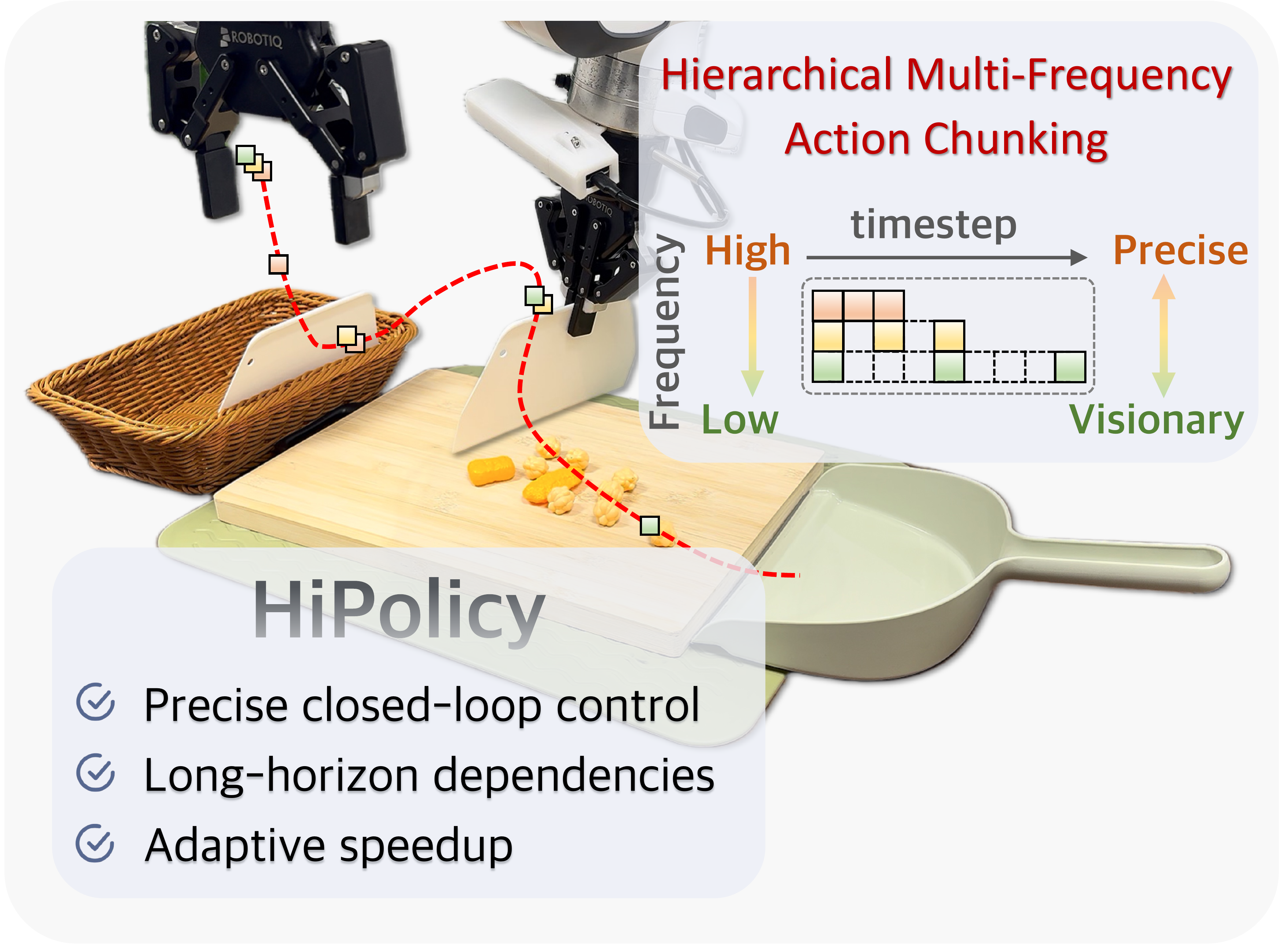
Robotic imitation learning faces a fundamental trade-off between modeling long-horizon dependencies and enabling fine-grained closed-loop control. Existing fixed-frequency action chunking approaches struggle to achieve both. Building on this insight, we propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies to capture both coarse high-level plans and precise reactive motions. We extract and fuse hierarchical features from history observations aligned to each frequency for multi-frequency chunk generation, and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. Experiments on diverse simulated benchmarks and real-world manipulation tasks show that HiPolicy can be seamlessly integrated into existing 2D and 3D generative policies, delivering consistent improvements in performance while significantly enhancing execution efficiency.
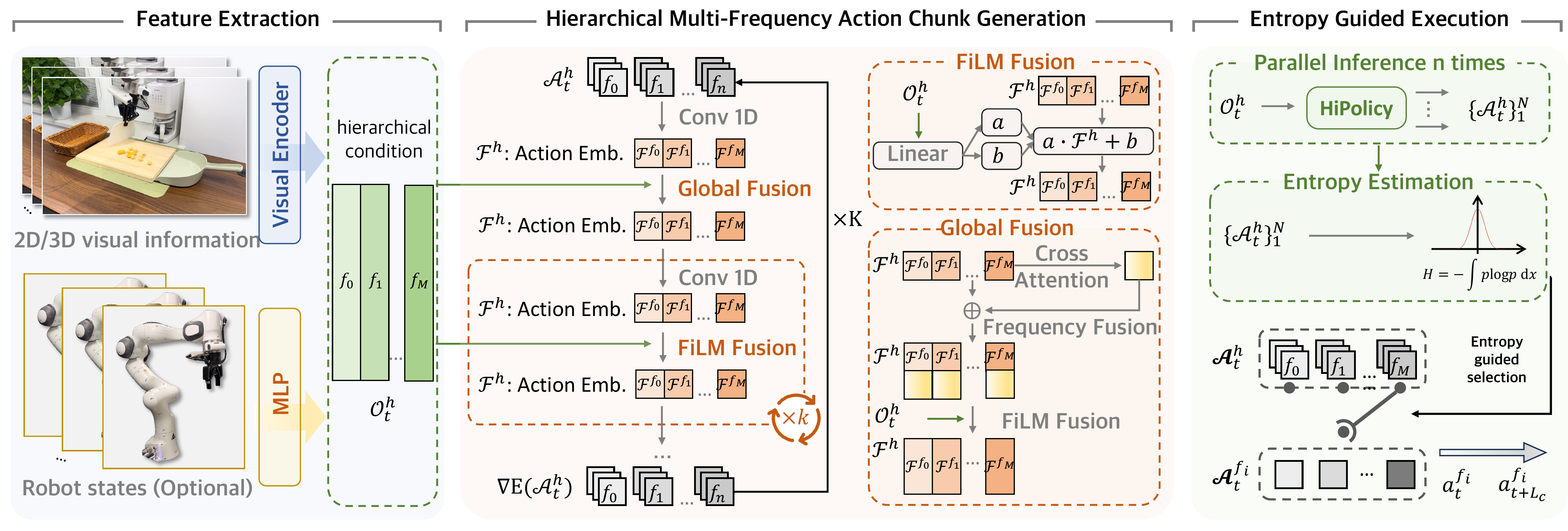
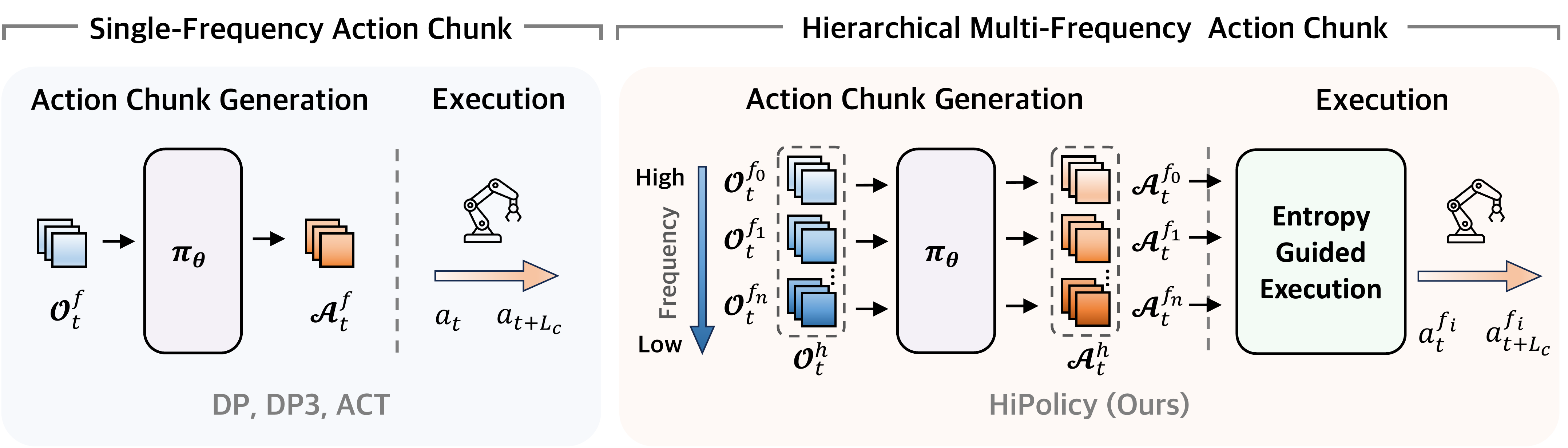
HiPolicy's core innovation is the hierarchical multi-frequency action chunking architecture that jointly predicts action sequences at multiple frequencies:
Generates short, fine-grained action chunks for precise reactive control and closed-loop adjustments.
Produces longer action sequences capturing high-level goals, stage transitions, and long-horizon intent.
Both branches are trained jointly with a combined loss, enabling the policy to learn complementary representations that capture both the "what" and the "how" of manipulation.
Another key innovation is the confidence-aware execution mechanism that dynamically selects which frequency to execute based on the policy's action distribution entropy:
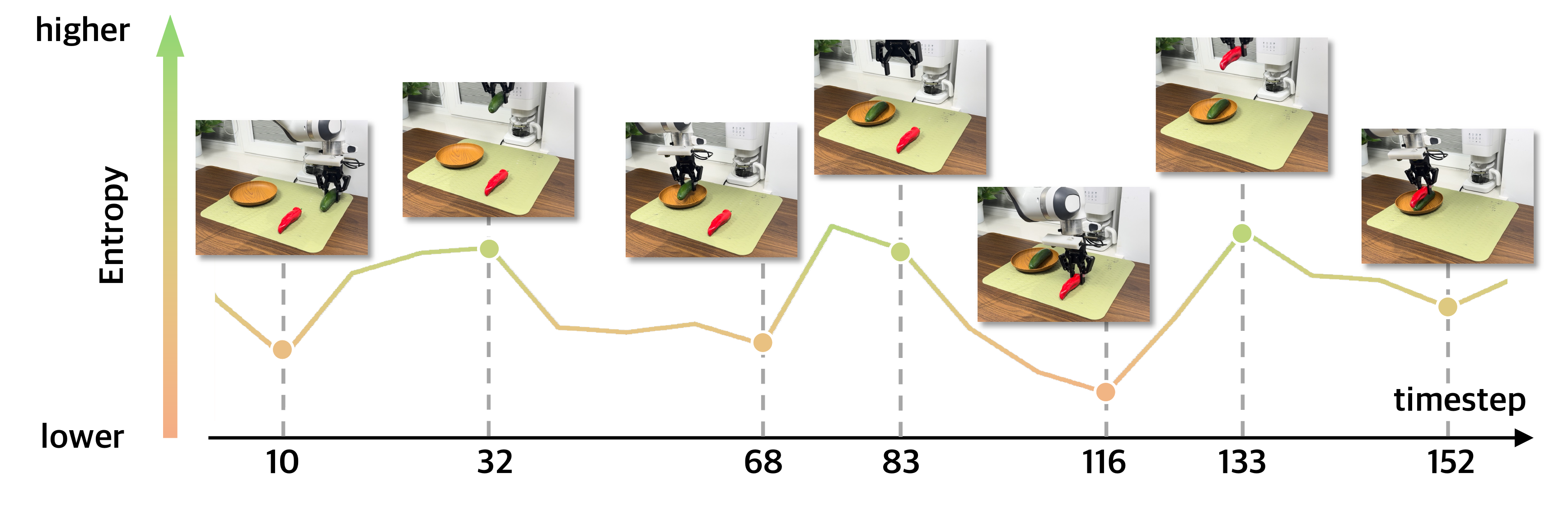
Stable predictions — execute high-frequency chunks for fine-grained and closed-loop control.
High uncertainty, indicating a phase transition — execute low-frequency chunks for broader planning, while increasing execution speed.
This adaptive mechanism ensures the robot acts precisely when confident and plans more broadly when uncertain, naturally balancing reactivity and deliberation without manual tuning.
100 evaluation episodes per task.
Hierarchical structure is the core contributor; fusion and multi-frequency conditioning both provide additive gains.
Test on 5 tasks from RoboTwin 2.0).
Eight real-world manipulation tasks: stacking cubes, sweeping a board, packing packages, placing vegetables, placing bowls, opening/closing microwave doors, and pressing toaster buttons.
@article{zhang2026hipolicy,
title={HiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning},
author={Zhang, Jiyao and Han, Zimu and Wang, Junhan and Wu, Xionghao and Lin, Shihong and Li, Jinzhou and Fan, Hongwei and Wu, Ruihai and Li, Dongjiang and Dong, Hao},
journal={arXiv preprint arXiv:2604.06067},
year={2026}
}